
A Chihuahua, a Labrador, and the Limits of Genetic Distance
A Lesson in Lewontin's Fallacy, Quantitative Genetics, and the Limits of FST

The image below presents a comparison that, at first glance, seems absurd.
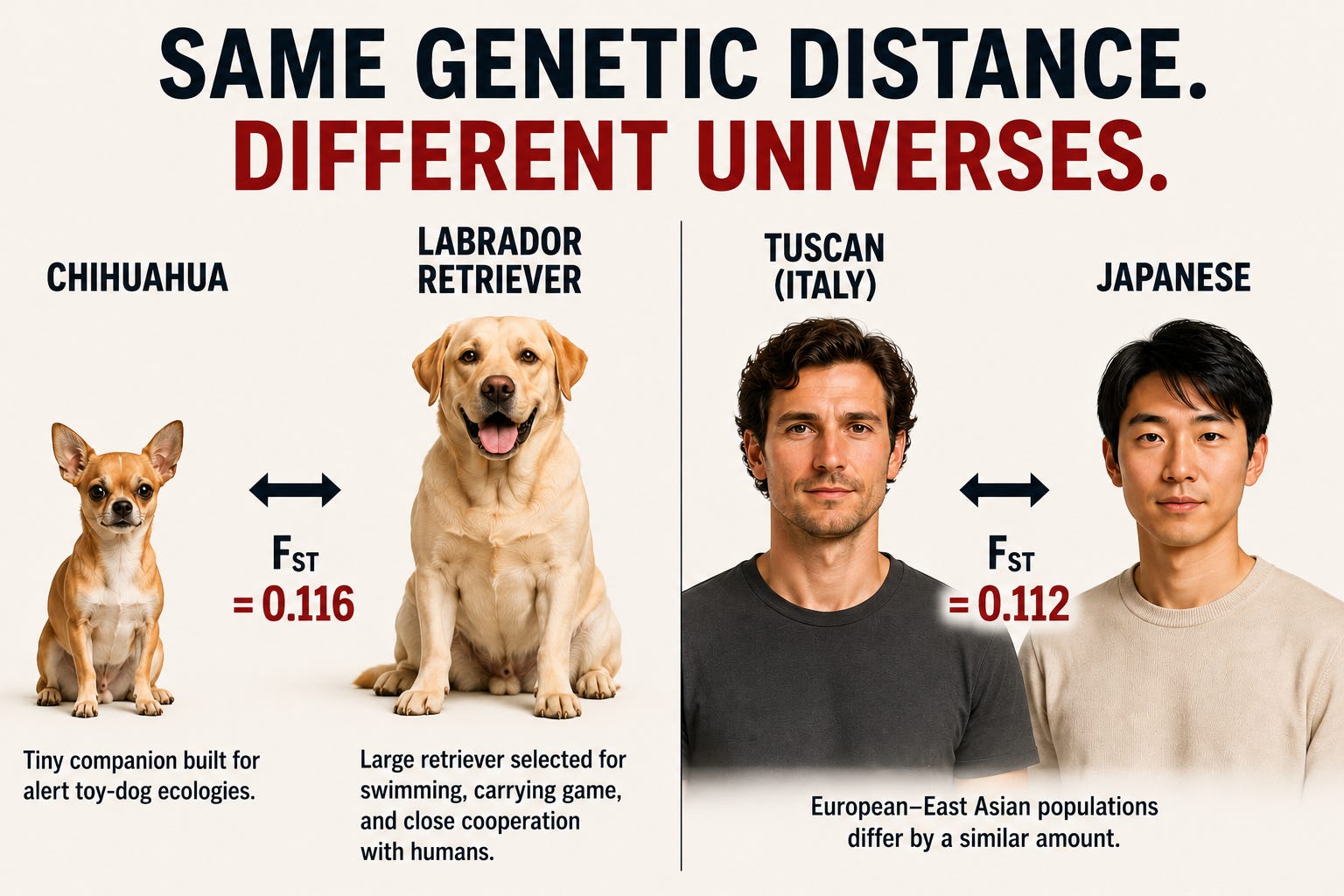
A Chihuahua and a Labrador Retriever differ dramatically in size, anatomy, behavior, and function. One is a tiny companion dog; the other is a large working retriever bred for swimming and carrying game.
Yet their genetic differentiation (FST = 0.116) is almost identical to several ordinary human intercontinental comparisons: northern Italians vs Japanese (0.116), southern Han Chinese vs northern Italians (0.116), Beijing Han Chinese vs Mozabites (0.116), and French vs Japanese (0.113).
This apparent paradox illustrates a central theme of this article: genetic distance and phenotypic difference are not the same thing. As we will see, FST is often treated as a universal ruler of biological difference, but that interpretation can be highly misleading.
There are countless dog and cat breeds, and they differ a lot in hair color, size, and even intelligence and personality. Consider the stark behavioral differences we take for granted: a Border Collie lives to herd livestock, a Siberian Husky is driven to pull sleds for miles, and a Cavalier King Charles Spaniel is content simply being a lapdog. Meanwhile, in the feline world, a Siamese is famously vocal and demanding of attention, while a British Shorthair remains placid, reserved, and fiercely independent.
Looking at these dramatic differences in appearance and behavior, an intriguing question naturally arises: how much do they differ genetically? And more provocatively, are the genetic differences between a Bulldog and a Chihuahua similar to those between different human populations?
When researchers want to measure this kind of genetic distance, they often reach for a mathematical metric called FST. But as it turns out, relying purely on this number to map out biological reality can lead us straight into a trap.
The Illusion of the Absolute Ruler
FST is often treated as if it were a simple, objective genetic distance ruler. The logic seems straightforward: put two populations into the formula, get a number, and then rank the distances. While that is undeniably useful, it is also dangerous.
The truth is that an FST value is not just pure, unadulterated biology. It is highly sensitive to the mechanics of the study itself, including:
Sample size (N)
Total marker count
Missing data (”missingness”)
Ascertainment bias
The specific way the population labels were built in the first place
To demonstrate how easily these numbers can be misinterpreted, I compared pairwise Hudson FST values across three distinct within-species datasets:
Humans: Modern human groups from the Allen Ancient DNA Resource (AADR) v66 2M panel (179 population labels, yielding 15,931 pairwise values).
Dogs: Purebred dog SNP data from the Parker 2017 dataset after quality control, minority allele frequency (MAF) filtering, and linkage disequilibrium (LD) pruning (177 breed labels, yielding 15,576 pairwise values).
Cats: Cat breed and random-bred groups from the Matsumoto SNP dataset after QC and LD pruning (14 group labels, yielding 91 pairwise values).
The concrete result of this comparison is surprising: human, cat, and dog FST values live on a remarkably similar numerical scale.
What Exactly Is FST Measuring?
At its core, FST measures allele-frequency differentiation. If two groups share very similar allele frequencies across many single-nucleotide polymorphisms (SNPs), the FST is low. If those frequencies differ significantly, the FSTis high.
However, because we must estimate allele frequencies from finite samples, small sample sizes introduce a massive amount of statistical noise. Because FST behaves like a distance metric, random noise inherently pushes groups apart, creating the illusion of large genetic separations where none exist.
The Data: Uncomfortably Close Distributions
When we look at the raw distributions, the overlap between species is striking. Cats are especially close to the human median, and while dogs are shifted higher, as you would expect from strictly closed, inbred breed structures, the vast majority of dog breed-pair values still sit firmly within the central human range.
Table 1: Pairwise Hudson FST Summary Statistics
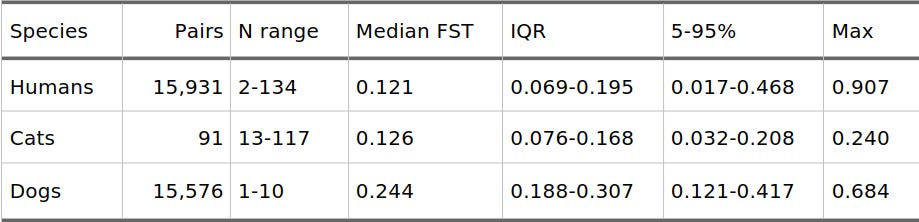
Using the human 5th-to-95th percentile range (0.017 to 0.468) as our baseline reference interval, we get a clear picture of just how much these distributions overlap:
Table 2: Overlap with the Human F_ST Distribution
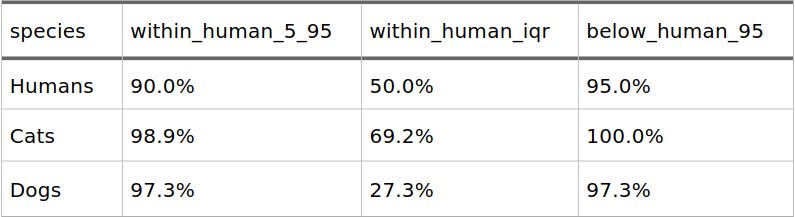
This means that 98.9% of cat breed comparisons and 97.3% of dog breed comparisons fall squarely inside the normal genetic distance range found between human populations.
The visual density plot below illustrates this dramatic overlap, highlighting how the mathematical distributions occupy the exact same territory:
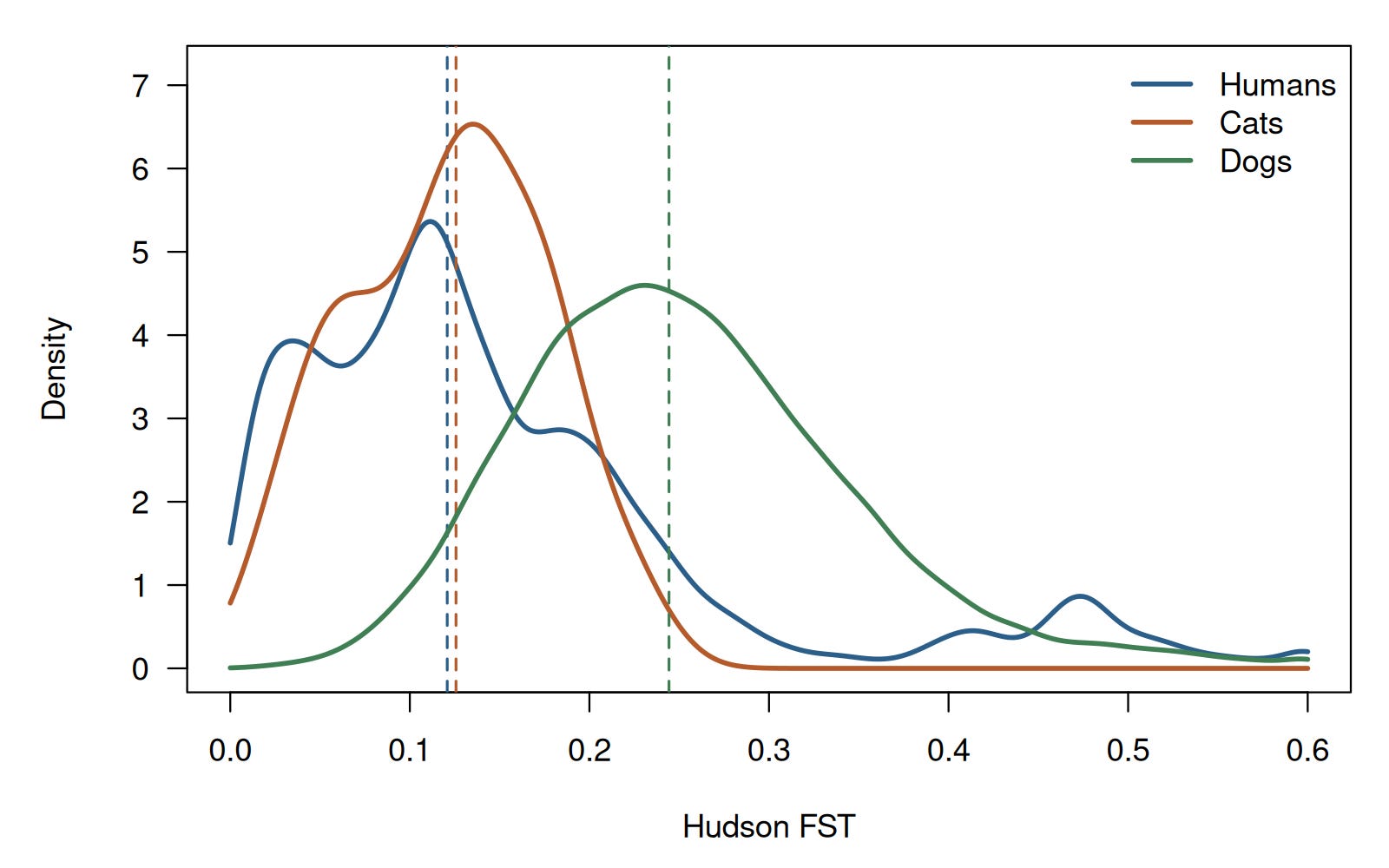
A Chihuahua and a Labrador can be separated by roughly the same FST as an Italian and a Japanese person.
So why don’t they look anything alike?
To answer that question, I match dog breeds to human population pairs with nearly identical genetic distances, reveal the complete cat FST matrix and an expanded matrix of major dog breeds, test the sample-size trap that inflates genetic distances, and explain the quantitative genetic logic behind Lewontin’s Fallacy.
Upgrade to a paid subscription to continue reading and access the full archive.
Your support directly funds the independent data pipelines, quality control, and computation required to turn raw genomic data into analyses like this one.
